Philosophy, Computing, and Artificial Intelligence
PHI 319. Understanding Natural Language.
Thinking as Computation
Chapter 8 (153-176)
Natural Language Processing
Human beings understand language. How do they do it?
This is not how Large Language Models achieve their understanding, if they have understanding. In these models, the meaning of a word is a vector in a high-dimensional space that represents the use of the word in the language. It might be that human beings, or any intelligent agent who understands natural language, must process the words they see and hear in terms of a lexicon and a grammar.
A Lexicon and A Grammar
A lexicon and a grammar define the grammatical strings of a language.
Here is a simple example:
s -> np vp
np -> det n
vp -> v np
vp -> v
det -> a
det -> the
n -> woman
n -> man
v -> loves
The symbols s, np, vp, det, n, and v stand for grammatical categories:
s: sentence
np: noun phrase
vp: verb phrase
det: determiner
s, np, and vp are non-terminal grammatical categories.
det, n, and v are terminal grammatical categories.
a, the, woman, man, and loves are the lexical items in the terminal grammatical categories.
The language consists in the set of strings (words strung together) formed from the lexicon and the grammar. Consider the following string of words from the lexicon
man woman loves the loves
This is a string of words in the lexicon, but it is not a grammatical string (and so not a sentence) because it is not grammatical (not permitted by the grammar of the language).
A Sentence of the Language
Consider the string of words a woman loves a man. Is this string grammatical?
The following parse tree shows that it is grammatical and thus is a sentence of the language:
s
|
|
/ \
np vp
| |
| |
/ \ / \
det n v np
/ \
| | |
a woman loves det n
| |
a man
A Recognizer Written in Prolog
A "recognizer" is a program that recognizes whether a given string is in the language. Here is a recognizer (written in Prolog) for the language given by the lexicon and grammar:
s(X,Z) :- np(X,Y), vp(Y,Z).
np(X,Z) :- det(X,Y), n(Y,Z).
vp(X,Z) :- v(X,Y), np(Y,Z).
vp(X,Z) :- v(X,Z).
det([the|W],W). (The vertical line ( | ) separates the head from the tail in the list.)
det([a|W],W).
n([woman|W],W).
n([man|W],W).
v([loves|W],W).
The recognizer works in terms of what are called
"difference lists."
We use difference lists because
they improve performance times. We do not need to understand the reasons why.
The list
[a,woman,loves,a,man]
is the difference
between the lists
[a,woman,loves,a,man,zombie]
and
[zombie]
A difference list represents a list in terms of a pair of lists. The list a difference list represents is the "difference" between the two lists. So, for example,
[a,woman,loves,a,man]
is the "difference" between the lists
[a,woman,loves,a,man] and [].
In the recognizer, the np predicate looks for a noun phrase at the beginning of the list. If it finds a noun phrase, it passes what remains in the list ([loves,a,man]) to the vp predicate. If it finds a verb phrase, and what remains is the empty list ([]), the query is successful.
An example helps show how this works. The query
s([a,woman,loves,a,man],[]).
asks whether the difference between the list
[a,woman,loves,a,man]
and the list
[]
is a list that contains a sentence of the language ([a,woman,loves,a,man]).
If, in the first rule in the recognizer program, we replace X with [a,woman,loves,a,man] and Z with [], then the query matches the head of the first rule. The query list thus becomes
np([a,woman,loves,a,man],Y), vp(Y,[]).
Prolog renames variables because sometimes unification is not possible otherwise.
Consider the KB
f (a, X).
Suppose the query is
?- f( X, b)
This query is a logical consequence of the KB
∀x f(a, x)
---------- ∀E
f (a, b)
---------- ∃I
∃x f (x, b)
Unification, however, without renaming, is not possible.
The variable Y in this query list clashes
with the variable Y in the rules.
So, to prevent mistakes in the
computation, we replace the variable Y so that the query
list becomes
np([a,woman,loves,a,man],Y1), vp(Y1,[]).
If, in the second rule, we replace X with [a,woman,loves,a,man] and Z with Y1, the first query in the query list matches the head of the second rule. So the query list becomes
det([a,woman,loves,a,man],Y), n(Y,Y1), vp(Y1,[]).
Now we have another variable clash. So we replace Y with Y2 so that the query list becomes
det([a,woman,loves,a,man],Y2), n(Y2,Y1), vp(Y1,[]).
If we replace Y2 and W with [woman,loves,a,man], then the first item on this query list matches the second fact about determiners in the recognizer. Now the query list is
n([woman,loves,a,man],Y1), vp(Y1,[]).
If we replace Y1 and W with [loves,a,man], then the first item on the query list matches the first fact about nouns in the recognizer. Now the query list is
vp([loves,a,man],[]).
This completes the computation for the noun phrase a woman. The computation for the verb phrase proceeds similarly, and it should be clear that the computation will eventually succeed.
Here is a screen shot of the recognizer at work:
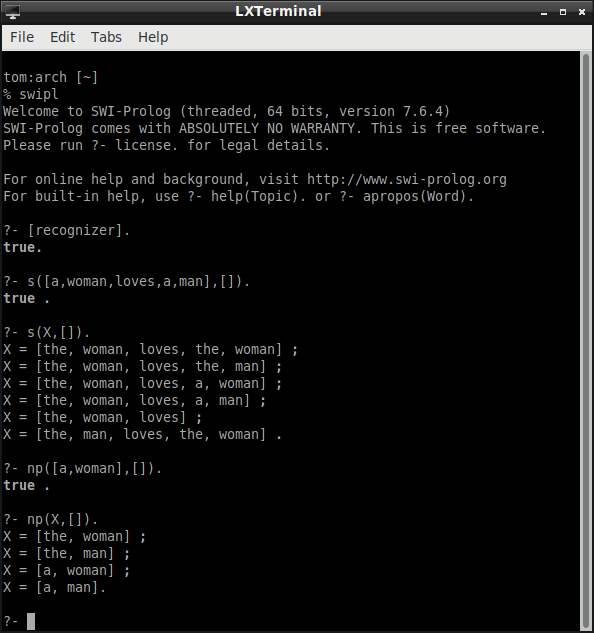
It is easy to modify the recognizer so that it displays the parse tree associated with the sentence:
s(s(NP,VP),X,Z) :- np(NP,X,Y), vp(VP,Y,Z).
np(np(DET,N),X,Z) :- det(DET,X,Y), n(N,Y,Z).
vp(vp(V,NP),X,Z) :- v(V,X,Y), np(NP,Y,Z).
vp(vp(V),X,Z) :- v(V,X,Z).
det(det(the),[the|W],W).
det(det(a),[a|W],W).
n(n(woman),[woman|W],W).
n(n(man),[man|W],W).
v(v(loves),[loves|W],W).
Again, an example makes it clearer how the program works. Suppose that the query is
s(T,[a,woman,loves,a,man],[]).
If we replace T with s(NP,VP), X with [a,woman,loves,a,man], and Z with [], then the query matches the head of the first rule. So the query list becomes is
np(NP,[a,woman,loves,a,man],Y), vp(VP,Y,[]).
The Y in this query list clashes with Y in the recognizer, so we replace it with Y1
np(NP,[a,woman,loves,a,man],Y1), vp(VP,Y1,[]).
If we replace NP with np(DET,N), X with [a,woman,loves,a,man], and Y1 with Z, then the first item on the query list matches the head of the second rule. Now the query list is
det(DET,[a,woman,loves,a,man],Y), n(N,Y,Y1), vp(VP,Y1,[]).
If we replace DET with det(a) and W and Y with [woman,loves,a,man], then the first item on the query list matches the second fact about determiners. The query list becomes
n(N,[woman,loves,a,man],Y1), vp(VP,Y1,[]).
At this point in the computation,
T = s(NP,VP)
NP = np(DET,N)
DET = det(a)
So, putting them together, T = s(np(det(a),N).
When we write T vertically, and replace the parentheses with branches, T is the following tree
s
/
np
/ \
det N
|
a
The rest of the computation works similarly.
It is clear that this computation will succeed and return the computed value of T.
Here is a screen shot of the modified recognizer program at work:
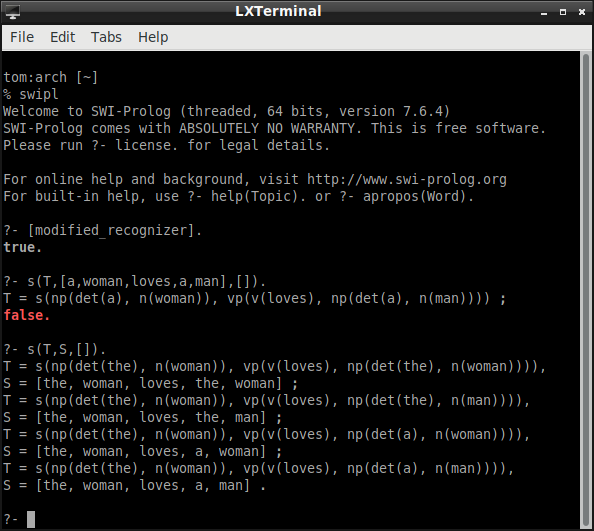
I took this printer, with slight modification, from a course on Prolog given at the 16th European Summer School in Logic, Language, and Information. To make the parse trees easier to read, we can add a "pretty printer."
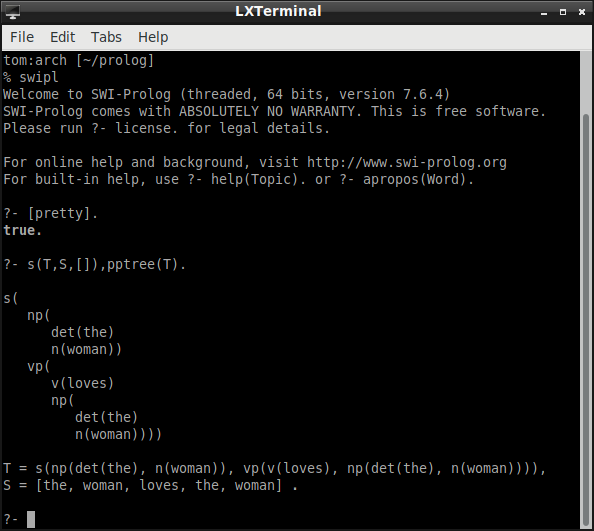
Models of the World
Understanding natural language requires more than the ability to recognize strings as grammatical. Understanding, it seems, requires knowledge of the truth conditions.
For this, we need a model of the world against which sentences are evaluated as true or false.
Here is an example mode, written in Prolog (nldb.pl), that Levesque provides:
person(john). person(george). person(mary). person(linda).
park(kew_beach). park(queens_park).
tree(tree01). tree(tree02). tree(tree03).
hat(hat01). hat(hat02). hat(hat03). hat(hat04).
sex(john,male). sex(george,male).
sex(mary,female). sex(linda,female).
color(hat01,red). color(hat02,blue).
color(hat03,red). color(hat04,blue).
in(john,kew_beach). in(george,kew_beach).
in(linda,queens_park). in(mary,queens_park).
in(tree01,queens_park). in(tree02,queens_park).
in(tree03,kew_beach).
beside(mary,linda). beside(linda,mary).
on(hat01,john). on(hat02,mary). on(hat03,linda). on(hat04,george).
size(john,small). size(george,big).
size(mary,small). size(linda,small).
size(hat01,small). size(hat02,small).
size(hat03,big). size(hat04,big).
size(tree01,big). size(tree02,small). size(tree03,small).
Recall that in a previous lecture we said that a model is an ordered pair <D, F>, where D is a domain and F is an interpretation. The domain D is a non-empty set. This set contains the things the formulas are about. This model can look confusing, but really it is pretty straightforward to understand.
In the world as represented by the model, there are things. There are four persons. Their names are "john," "george," "mary," and "linda." There are two parks. There are four trees, and so on. In addition to the objects in the domain (the people, parks, and so on), the model specifies certain basic truths about the relations in which the things (the objects in the domain) stand.
The model is thus a representation of things in the world.
The connection of words to things in the world is given in terms of the "extensions" of the words to things in the world. The rules that define these extensions are in the lexicon.
Here is an example (lexicon.pl) that Levesque provides:
article(a). article(the).
common_noun(park,X) :- park(X).
common_noun(tree,X) :- tree(X).
common_noun(hat,X) :- hat(X).
common_noun(man,X) :- person(X), sex(X,male).
common_noun(woman,X) :- person(X), sex(X,female).
adjective(big,X) :- size(X,big).
adjective(small,X) :- size(X,small).
adjective(red,X) :- color(X,red).
adjective(blue,X) :- color(X,blue).
preposition(on,X,Y) :- on(X,Y).
preposition(in,X,Y) :- in(X,Y).
preposition(beside,X,Y) :- beside(X,Y).
% The preposition 'with' is flexible in how it is used.
preposition(with,X,Y) :- on(Y,X). % Y can be on X
preposition(with,X,Y) :- in(Y,X). % Y can be in X
preposition(with,X,Y) :- beside(Y,X). % Y can be beside X
% Any word that is not in one of the four categories above.
proper_noun(X,X) :- \+ article(X), \+ adjective(X,_), \+ common_noun(X,_), \+ preposition(X,_,_).
Consider the first line, "article(a). article(the)."
It says that the words a and the belong to the grammatical category of article.
Consider the first rule, "common_noun(park,X) :- park(X)."
Recall that in a model is an ordered pair <D,
F>, the interpretation, F, is a function on the
non-logical vocabulary. It gives the meaning of this vocabulary relative to the domain.
For every constant c, F(c) is in D. F(c) is the referent
of c in the model.
For every n-place predicate Pn,
F(Pn) is a subset of
Dn. F(Pn) is the
extension of Pn in the model.
"kew_beach" and "queens_park" are constants.
The referents of "kew_beach" and "queens_park" are in D.
F("park") is the set {kew_beach, queens_park}.
It says that something (the value of the variable "X") is in the extension of the word park in the grammatical category common noun if this thing (the value of "X") is a park.
Consider the fourth rule for the category of common noun.
This rule says that that something (the value of the variable "X") is in the extension of the word man in the grammatical category common noun if this thing is a person and male.
We can write a program that determines if an object is in the extension of a noun phrase.
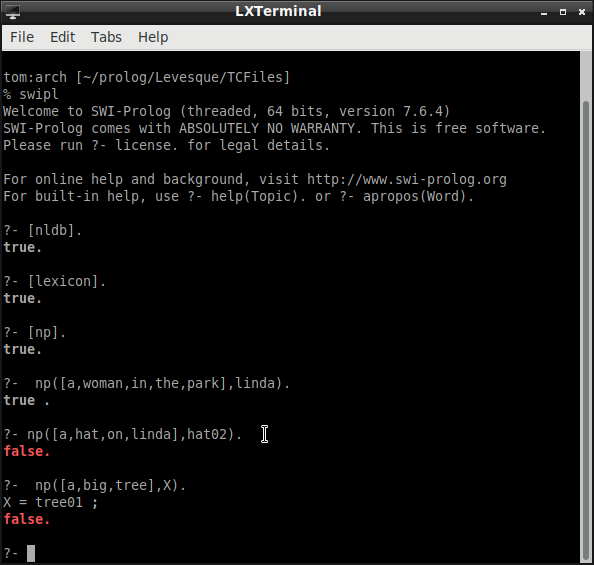
Given the model and lexicon, the query
np([a,woman,in,a,park],linda)
succeeds because "linda" is the name of something in the extension of "a woman in a park."
On the other hand, the query
np([a,hat,on,linda],hat02)
fails because the hat whose name is "hat02" is not in the extension of "a hat on Linda."
Here is the Prolog program (np.pl) Levesque provides:
np([Name],X) :- proper_noun(Name,X).
np([Art|Rest],X) :- article(Art), np2(Rest,X).
np2([Adj|Rest],X) :- adjective(Adj,X), np2(Rest,X).
np2([Noun|Rest],X) :- common_noun(Noun,X), mods(Rest,X).
mods([],_).
mods(Words,X) :-
append(Start,End,Words), % Break the words into two pieces.
pp(Start,X), % The first part is a PP.
mods(End,X). % The last part is a Mods again.
pp([Prep|Rest],X) :- preposition(Prep,X,Y), np(Rest,Y).
Consider the noun phrase "a big tree." The corresponding parse tree is
NP
|
/ \
article NP2
| |
| / \
| adjective NP2
| | |
| | / \
| | common_noun Mods
| | |
a big tree
Here is in the computation to determine if tree01 is in the extension of "a big tree":
np([a,big,tree],tree01) query
| np([Art|Rest],X) :- article(Art), np2(Rest,X)
| Art = a, Rest = [big,tree], X = tree01
article(a), np2([big,tree],tree01)
| article(a) succeeds; matches fact in lexicon
|
np2([big,tree],tree01)
| np2([Adj|Rest],X) :- adjective(Adj,X), np2(Rest,X)
| Adj = big, Rest = tree, X = tree01
adjective(big,tree01), np2(tree,tree01)
| adjective(big,X) :- size(X,big)
| X = tree01
size(tree01,big), np2(tree,tree01)
| size(tree01,big) succeeds; matches fact in model
|
np2(tree,tree01)
| np2([Noun|Rest],X) :- common_noun(Noun,X), mods(Rest,X)
| Noun = tree, Rest = [], X = tree01
common_noun(tree,tree01), mods([],tree01)
| common_noun(tree,X) :- tree(X)
| X = tree01
tree(tree01), mods([],tree01)
| tree(tree01) succeeds, matches fact in model
|
mods([],tree01)
| mods([],tree01) succeeds, it matches mods([],_)
|
| The symbol _ (called the "underscore") is the anonymous variable.
| It indicates that the variable is solely for pattern-matching. The
| binding is not part of the computation process.
the query succeeds!
What we have Accomplished in this Lecture
We considered some ideas in natural language processing (NLP). We considered how a lexicon and grammar together define the sentences (the grammatical strings) in a language. We considered a Prolog program that recognizes whether strings are sentences in the language and generates their parse trees. We saw how a lexicon can be built relative to a model so that a Prolog program can answer questions about whether an object is in the extension of a noun phrase. The computations in these programs begin indicate how natural language processing might be incorporated into the logic programming/agent model of a rational agent.

